TiDB 的异步 schema 变更优化
近一年我们在 DDL 方面做了一些优化,可能跟原来介绍 DDL 实现的文章有许多出入。所以这次介绍一下近期的一些优化,这些优化是在之前分享过一篇关于 TiDB schema 异步变更实现的文章的基础上做的。看优化前建议先看一下之前的实现。
概述
原来我们根据 Google F1 的在线异步 schema 变更算法实现的 DDL 功能,兼容了一下常用的 MySQL DDL 语句。目前在实际应用中有一些不足,主要分为两个部分,一方面是功能上支持的不够全面,一方面是运行时间上有些慢。
就刚提到的第一个方面,我们也在根据用户的要求添加功能,当前功能欠缺的情况可以参考与兼容 MySQL 情况。当然我们非常欢迎社区朋友向 TiDB 提 DDL 相关的 PR。 关于第二个方面,其实是因为用户的需求也是与时俱进的,从一开始业界几乎停业务更新 schema 的状况,到 TiDB 支持异步更新 schema,现在希望尽可能快的在线异步更新 schema。当然这是一个符合发展规律的需求,也是 TiDB 一定会满足的需求。那么我们是怎么来满足这个需要,首先需要详细介绍一下,原来在这方面的具体不足。
性能优化缘由
这里会简要说明一下在优化前执行 DDL 操作遇到的一些性能问题。 从整体角度上看,每个 DDL 操作的时间都是依赖 lease 的设置,每个状态变更需要 2 * lease,那么每个 DDL 操作至少是 2 * lease。而且 lease 为了安全起见至少是 1s,有些线上用户一开始会谨慎的设为 10s。那么一个 create table 操作,什么也没做,这个操作至少要执行 2s(lease=1s)。 从某些特殊操作,例如 add column 或者 add index,因为可能涉及实际的修改数据,由于数据量大的原因,整个操作会特别慢。 接下来我们会具体展开,从整体优化和特殊操作优化分别介绍优化的内容,当然也少不了对将来优化的规划。
整体优化
具体优化内容
将 owner 选举放在 PD 上处理,并用 PD 通知所有 TiDB DDL 状态变更的情况。前者可以略微减少 TiKV 压力,也解决用本地时间选取 owner 的隐患,后者可以减少每个 DDL 操作处理的等待时间。
Owner 选举
每个 DDL 对应一个竞选 owner 的 goroutine,它用来判断此 DDL 是否为 owner。也就是说与原来逻辑一样,每个 TiDB 的 DDL 知道自己是否为 owner,不知道其他 TiDB 的 owner 信息。 具体方法是用 PD 中内嵌的 etcd 接口,通过 Session 创建的 Election 调用 Campaign 接口进行 owner 选举。如果选举成功,那么将此 DDL 设置为 owner ,并监听这个 owner 对应的路径,那么当它不是 owner 时,可以收到通知,更新自己为非 owner 的信息。如果选举不成功,那么它为非 owner, 并一直排队,等到选举成功后做选举成功的流程。
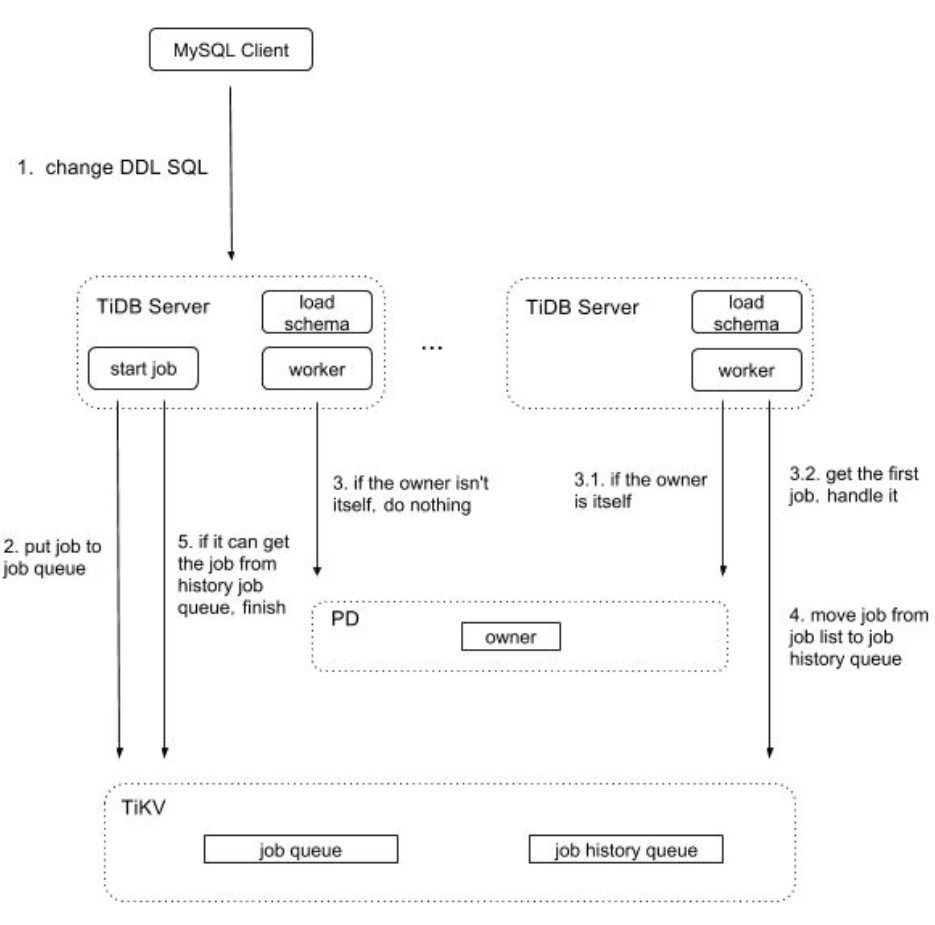
通知状态变更形式
状态变更原逻辑(优化前)
分两方面:
- 所有 TiDB 接收状态变更的方式:被动的每隔 0.5 * lease 需要 load 一次 schema 信息,确保当前的 schema 是有效的;
- owner 在变更完一个消息后,需要等待 2 * lease,确认集群中所有 TiDB 都已经接收到此变更的消息。
状态变更新逻辑(优化后)
准备工作
第一台启动的 TiDB,在 PD 建立一个 latest version 信息路径,里面存有最新的 schema version 号。 所有 TiDB 启动时需要做如下操作:
- 将自身的 DDL ID(能确保唯一 ID) 以及初始 self version 号注册到 PD;
- 进行 load schema 操作,成功后更新 self version 号。
- 监听 latest version 信息。
对比原逻辑
对于具体流程的细节就不在这里描述了,对应原来逻辑分别是:
- 所有 TiDB 会 watch 当前最新的 schema version。当接收到最新 schema version 更新的通知时,会 load 最新 schema,并将此 TiDB 对应的 shema version 更新到 PD。其中被动 load schema 的操作还是会保留,以防 watch 消息不及时或者丢失。 流程如图 2。
- owner 在变更完一个状态后,将最新的 schema version 更新到 PD,等待几十毫秒用于所有 TiDB 更新最新 schema 信息。之后通过 PD 查看是否所有 TiDB 都更新到此状态,如果全部 TiDB 都更新到最新 schema version,则不需要等待 2 * lease,直接进入下一个流程。如果这里跟 PD 有交互问题或者集群中有个别 TiDB 没能更新到最新 schema version,那么降级到原来等待 2 * lease 的情况处理(具体用超时时间处理)。流程如图 3 中 opt 流程。
当然这个还涉及许多细节,也需要更新 TiDB 原本对 information schema 的有效性的处理,由于内容有点多,就不在这里细说了。
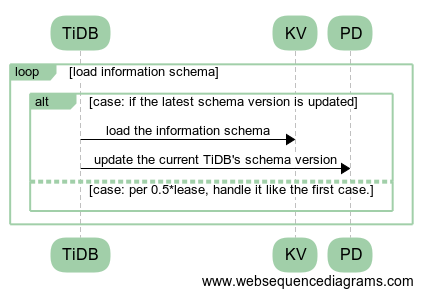
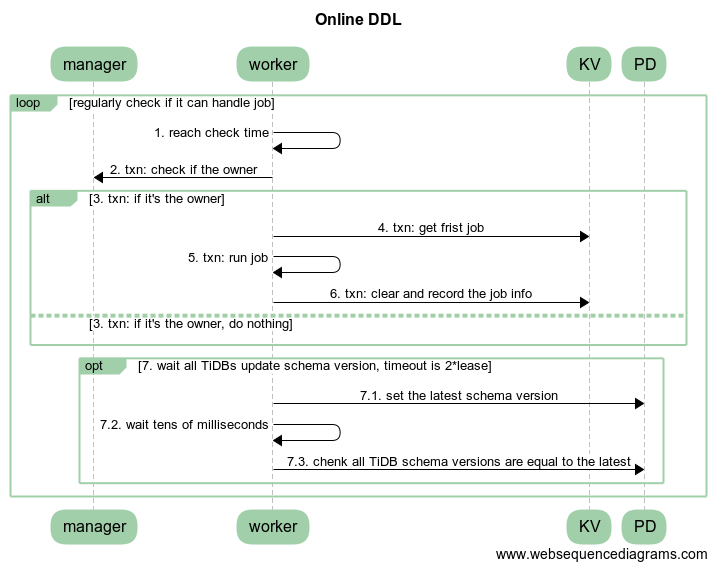
移除 TiDB Sever 信息
将断联的 TiDB Sever 信息从 PD 中移除,减少由于某台 TiDB Server 出现网络分区或者挂机的情况,导致 DDL 处理都需要等待 2 * lease。首先在一开始的时候将 TiDB Server 的信息改存为 TTL 的结构,设置超时为 max(10 min)。其次在 TiDB 接收到退出信号时,主动像 PD 发出清理请求。
效果
第一个优化,可以减少每个 TiDB 在一秒内对 TiKV 的访问次数。第二个优化,将一个 DDL 操作的执行时间从原来几秒到几十秒(具体依据 lease 的设置)减少到现在的几十毫秒。
特殊操作优化
drop 操作优化
对于原来 drop schema、drop table 和 drop index 等操作,在真正删除数据时,用 delete range 的方式替换原来放到后台处理的操作流程。 在前面举例的操作结束时,将对应的表信息和 range 信息(即数据的起始 key)记录到内部的特定表中。真正的清除数据的操作,是由 TiDB GC worker,在清理其他过期数据时同时清理。这个操作的优点,其一是把原来 background 部分的代码可以全部清理,不需要维护两部分类似代码;其二是它是直接调用 TiKV 的接口直接清理数据,不需要 TiDB 一批一批串行的清理数据,即方便又省各种资源。
Add Column 操作优化
这个优化效果会特别显著,因为实际上我们最后没有存那些数据。那么整个操作就不关心表的数据行数,整个操作只需要进行 5 个状态的变更即可。此操作前后做了两个优化: 新加列的 Default Value 是一个空值,那么就不需要实际的去填充。之后对此列的读取时,从 TiKV 返回的列值为空时,查看此列的元信息,如果它是 NULL 约束则可直接返回空值(这逻辑会在 Coprocess 处理)。 新加列的 Default Value 的值为非空的情况下,也不用将 Default Value 存储到 TiKV,只需将此默认值存到一个 schema 的字段(Original Default Value)中。在之后做读取操作时,如果发现 TiKV 返回此列的的值为空,且这个 schema 字段中的值为非空,那么将此字段中的值填充给这一列,然后返回(这逻辑会在 Coprocess 处理)。
Add Index 操作优化
原先 add index 最后填充数据就是通过批量处理。这样做是为了防止此操作的事务与其他在操作此 index 的事务发生冲突,导致整个 add index backfill 的操作重试从而进行分批处理。但是这个批量不是并发处理,只是为了减少冲突域做的。优化前串行逻辑是先扫一批 key,扫完之后对这批 key 的值进行修改。针对这个操作我们目前做了两次主要的优化。
第一次优化
此次优化主要分两部分:
- 减少对 TiKV 的访问,用 BatchGet 代替 Get,移除不必要的 Exist 的调用等。
- 对一些操作进行并发处理。此处的并发处理比一般的略微复杂,即真正的并发是在扫完一批 key 后对其进行的解析及真正修改 key 的值的处理。虽然每个 key 区间的长度可控, 但是这个区间的具体值由于一些删除操作不可预计, 所以需要串行地获取一批 key。这个优化用 go 处理还是特别方便易懂。通过一个小集群进行一定数量的对比测试后,请求执行时间大约是优化前的 ⅓ (具体需考虑表中数据行数,这些测试中表行数最少也是上万行)。其中并发个数是通过优化效果和冲突域两个参考值权衡下调整的。
第二次优化
此优化也分为两部分:
- 读写数据模式改为一次有多个 worker 并发的读写特定区域(handle range)数据,然后等待这次操作结束进行下一次操作。这个特定区域是用 handle 直接推测区间,那么可能会推测不准确,所以做了如下调整:
- 如果出现读的时候,读到的 handle 远大于此 worker 需要读 handle 区间的 end handle(说明此间有大批 handle 是无数据的),那么记录此 handle,更正下一次并发读时几个 worker 的 handle 区间,减少无用操作。
- 如果读取数据个数小于设定值,会动态调整 handle 区间。
在数据连续的情况下,能减少约 22% 的耗时(数据量在 1 亿行,4 个 TiKV,1 个 PD,2 TiDB)。但是 handle 可能被批量删除过或者插入时就是非常离散等原因,还是会使整个操作变慢,所以新的优化在计划中。
- 增加一些内存复用,从 profile 还是能看到有不少优化。
辅助功能
Show DDL jobs
希望查看当前 DDL 正在运行、等待运行以及已执行完成的 DDL job 时可以使用的语句。具体 SQL 语句如下:
ADMIN SHOW DDL JOBS
Cancel DDL jobs
由于目前 DDL 操作都是串行执行的,操作人员由于手误或者手动重试,导致在一个大表上多次执行 add index 这种耗时比较久的操作,希望取消这个 DDL 语句的执行时,可以使用这个功能。具体 SQL 语句格式如下:
ADMIN CANCEL DDL JOBS 'job_id' [, 'job_id'] ...
计划与总结
计划
性能优化部分,我们目前在计划中的是 DDL job 按 table 级别并行执行,以及 add index 操作的加速工作。前者考虑从适当的添加处理的 worker 开始。后者会从分离读写数据操作,进行并行处理;读取数据时考虑剪枝;以及考虑更准确的方式估测 handle 区间等多个方面着手。当然还有兼容性方面,目前我们还是会根据用户实际需求进行更全面的兼容 MySQL 的 DDL 操作。另外,DDL 测试方面也会添加更多针对性的集成测试。
问题
如果大家有发现 DDL 请求处理慢的情况,可以查看可能原因,如果都不是可以第一时间联系我们(如果是外部人员,可以提 issue),也希望大家能保存当时的日志。这里再说明一下关于 MySQL 的兼容性情况。
总结
最后,PingCAP 在持续火热招聘中,欢迎大家加入我们,也非常欢迎大家给 TiDB 提 PR,不管是入司还是在外部的人员,特别感谢!